问题描述
收了一个华硕 Z77 平台的 p8z77-v lx2, 但是使用 DP 线插在显卡(我的是980ti)上进入系统时黑屏,具体表现为无法看见 BIOS 启动画面。但是如果换成 HDMI,DVI 线则可以看到。
解决方案
英伟达有一个固件升级工具

下载该工具更新显卡固件即可解决
参考链接
在 WEB 开发技术中, 字符串插值是一种很常用的操作, 在各种 Web 前端框架中都能看到其身影.
例如 VUE 中, {{ }} 用两个大括号包裹住可以表示一个表达式
简言之, 此时我们有变量
1 | name = "naonao" |
那么上面的 HTML 模板最终会被渲染为
1 | <p>naonao</p> |
我们可以实现一个render函数, 像这样
1 | def render(templates: str, values: Dict[str, str]) -> str: |
目标
{{ }} 包裹住的变量需要清除其前后的空白字符, 例如 {{ name }}, {{name}}, {{ name}} 都是等价的特别的
这些也应当是有效变量, 他们最终会被识别为
1 | "{name}" |
如何实现呢?
1 | from typing import Dict, List, Tuple |
验证下效果
1 | strings = [ |
1 | |nao is, 16| |
达到预期效果!
Odoo Challenge 挑战赛是一个很有意思的项目, 起源于一次面试时, HR发来个链接说测试一下水平.
好了, 开始挑战
先随便输一个密码, 点 Check Answer, 很不意外的密码错误, 不过这时候有提示, 可以根据提示的线索来找到密码.
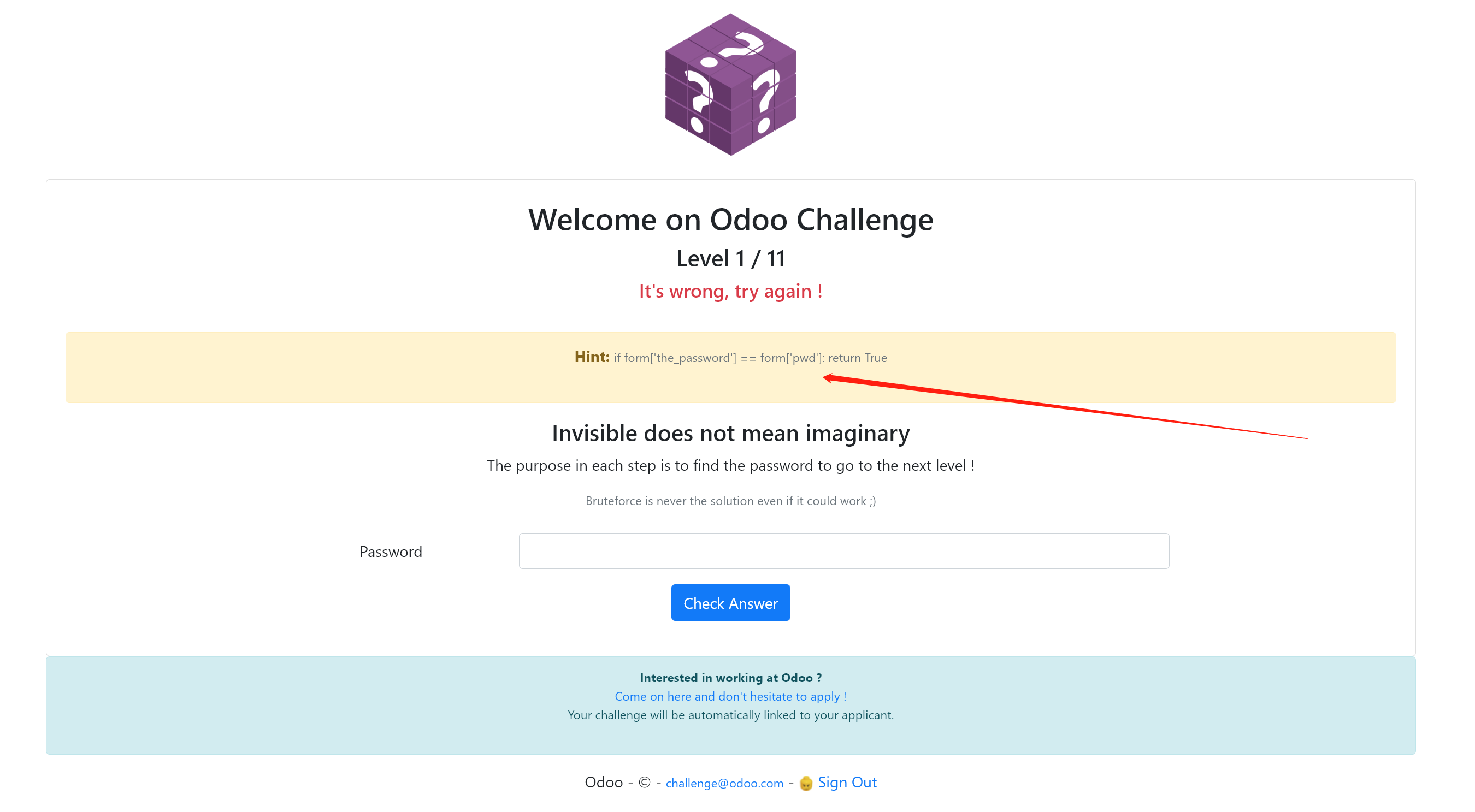
看到提示
1 | Hint: if form['the_password'] == form['pwd']: return True |
看看网页的源码, 猜测应该在里面能找到.
部分源码
1 | <form method="POST" action="/jobs/challenge/submit" role="form"> |
注意到
1 | <input type="hidden" name="the_password" value="796ff3e72821cf412787389c6d5f301e00e3efb6"/> |
1 | 796ff3e72821cf412787389c6d5f301e00e3efb6 |
就是本关的密码了
第二关提示如下
1 | Hint: function debug() { [native code] } |
猜测应该是和 debug 有关系, 所以可以 F12 打开开发者工具在命令控制台标签页找线索
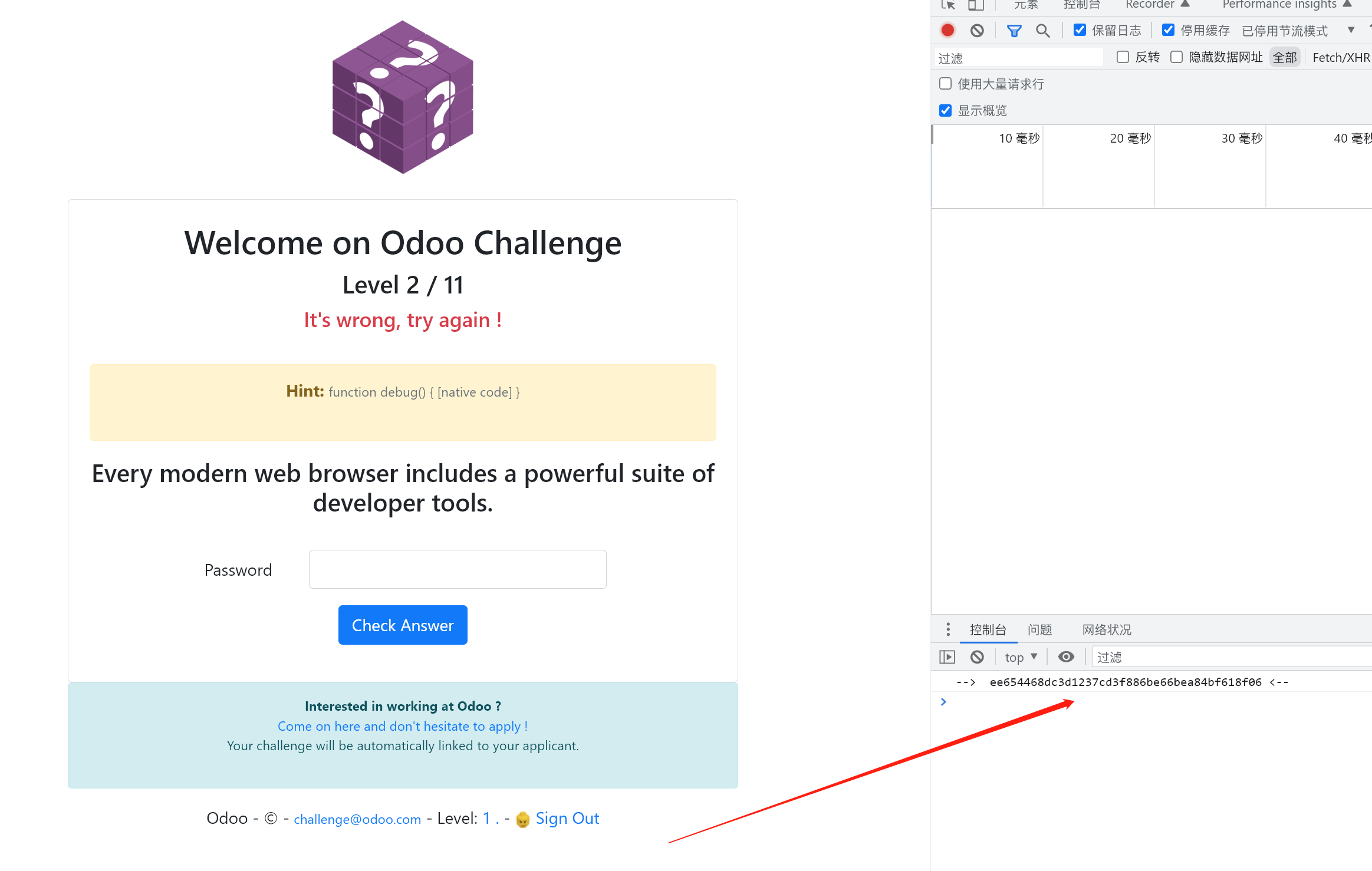
直接出答案了
提示
1 | Hint: GET / HTTP/1.1 |
猜测应该在与服务器交互的请求里寻找.
我们随便输一个密码, 提交一下看看与服务器的交互请求都有哪些
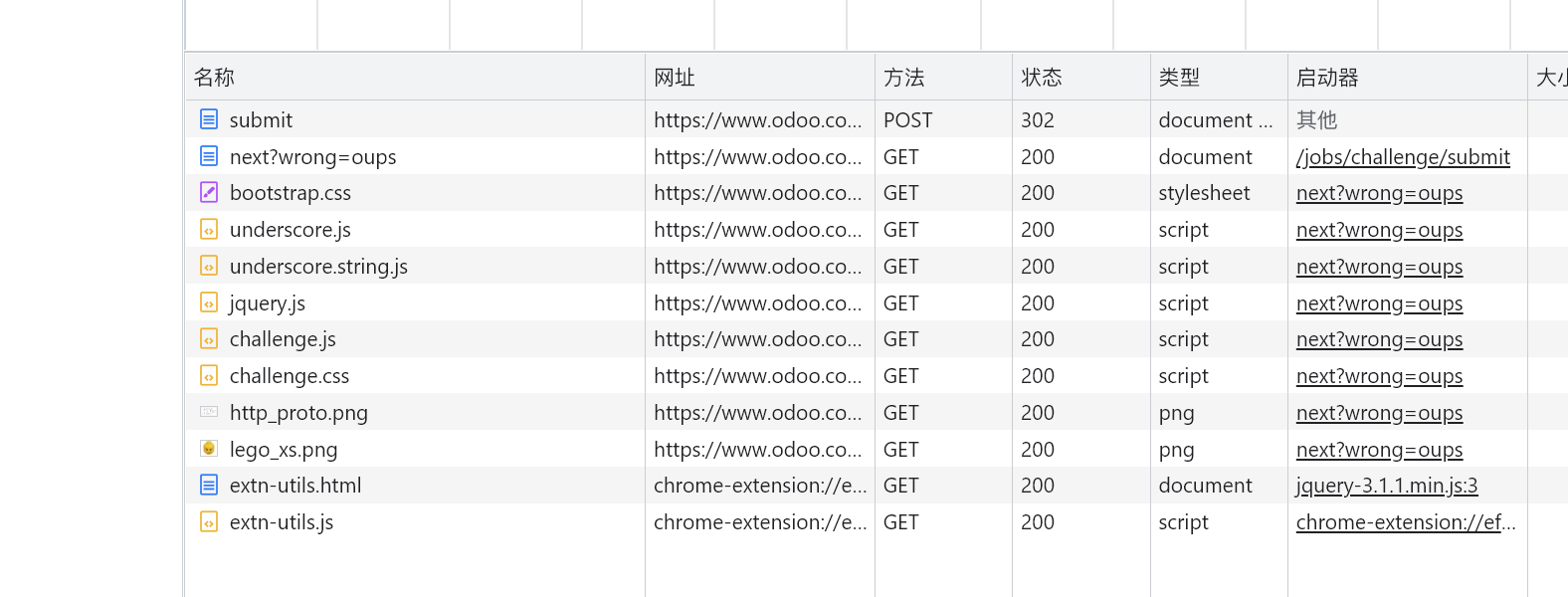
每个请求都点开看一看 request / response 里面有没有什么可以寻找的线索.
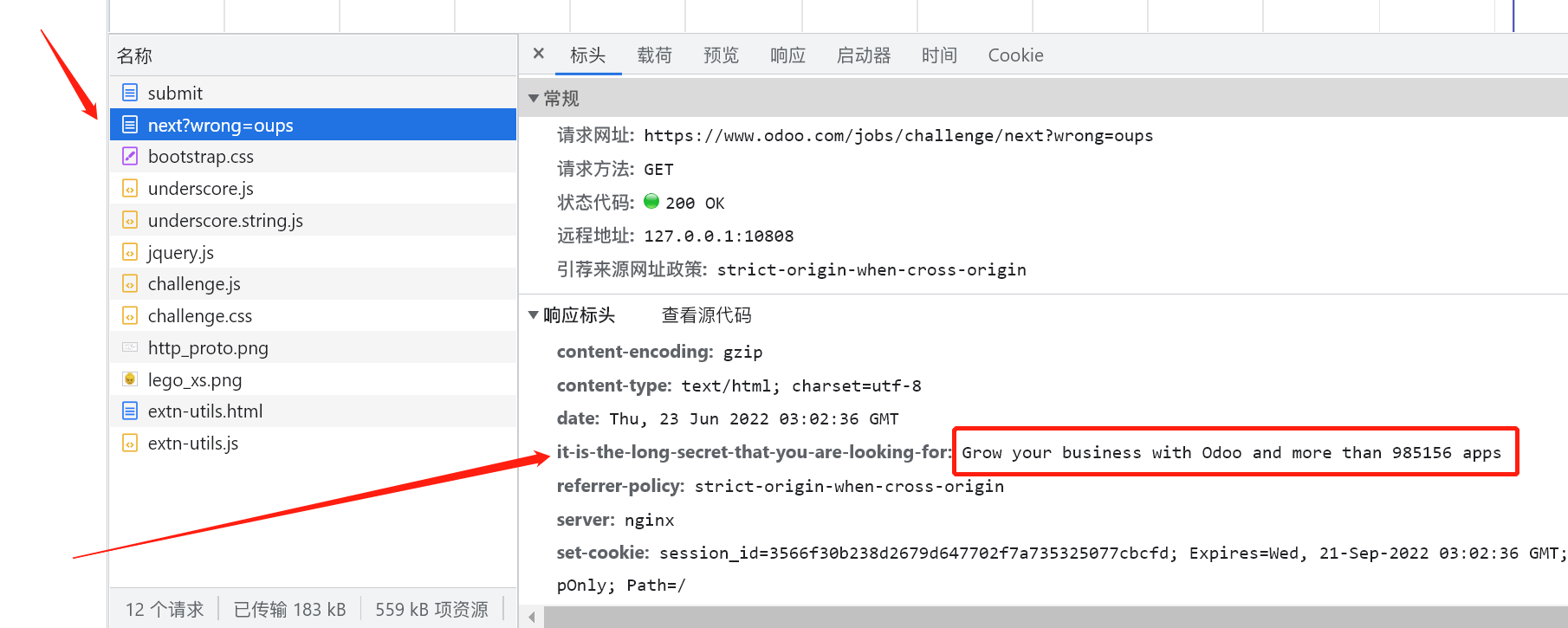
可以看到在 next?wrong=oups 这个请求的响应头里面有内容, 红框标记的猜测应该是答案, 即
1 | Grow your business with Odoo and more than 985156 apps |
提示
1 | Hint: Classy password |
笔者在解决这个问题的时候花费了相当长的时间。最开始我猜测提示经典密码也许有可能是弱口令?
我试了如下弱口令
1 | admin |
诸如此类的弱口令发现都没有用。
最后我写了一个脚本, 从 Github 上找了找有没有彩虹表, 常用弱口令之类的仓库.
找到一个 https://github.com/rootphantomer/Blasting_dictionary

挂着跑了一下午, 回来一看跑了大概 2w 个密码仍然没有任何起色. 这个时候我开始怀疑一开始的思路是否正确, 提示经典密码的意思究竟是不是弱口令的意思?
但是此时我又没有更好的思路, 于是每个请求都翻了翻, 看看有没有有用的信息.
真让我翻到了….

1 | https://www.odoo.com/jobs/challenge/challenge.css |
这个请求的内容就是密码….
呵呵, 踏破铁鞋无觅处…
这个事情告诉我什么道理呢, 如果一个题目看起来很简单, 但是通过暴力方法很难解决时, 一定要寻找其他的突破口….

提示
1 | Hint: I'm a small piece of data sent from a website and stored on the user's computer |
意思是服务器发送了一个数据片段存储到了用户电脑上.
看到这个首先想到 local storage 和 cookies
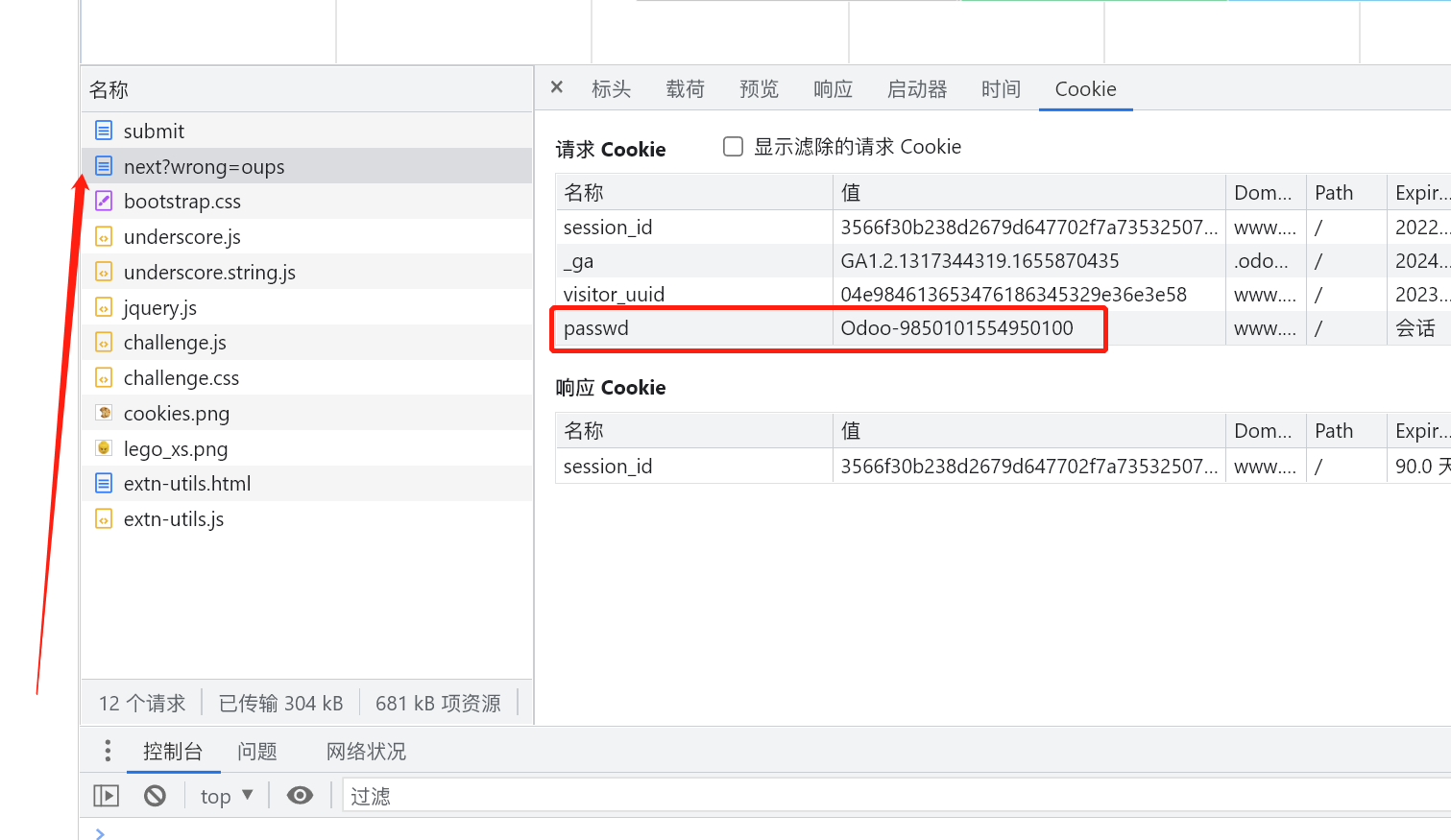
印证了我的想法, 我在请求
1 | https://www.odoo.com/jobs/challenge/next?wrong=oups |
里发现了线索, 密码既是方框里的值
1 | Odoo-9850101554950100 |
PS: 事后我发现这个页面的图标是一个饼干.
cookies 的意思正是饼干. 看来还是要多观察不一样的细节.

给了一段 js 代码
1 | // JS |
看来一下逻辑, tmp 变量存储的应该是 idx 字符串的索引, 我们把索引对应的字符取出来即可.
可以用 Python 实现一个简单的解码函数
1 | idx = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' |
得到密文
1 | 2CDA4eb85c13B7105e80 |
本关通过

哈哈, 从现在开始难度增加了…..
提示
1 | Hint: ascii |
ascii 码? 这个提示…..简单到等于没什么提示…
还是去翻一翻请求, 看看 request / response / cookies 有什么线索吧.
首先在控制台看到打印了一串信息

翻译了一下大概是说需要调用另一个 URL 来执行下一个任务.
然后在请求
1 | https://www.odoo.com/jobs/challenge/next?wrong=oups |
里发现了不少信息.

这个地方有一个奇怪的信息, 我们先记一下.
| name | value |
|---|---|
| It-Is-The-Part-2-Of-Url | “/jobs/challenge/ |
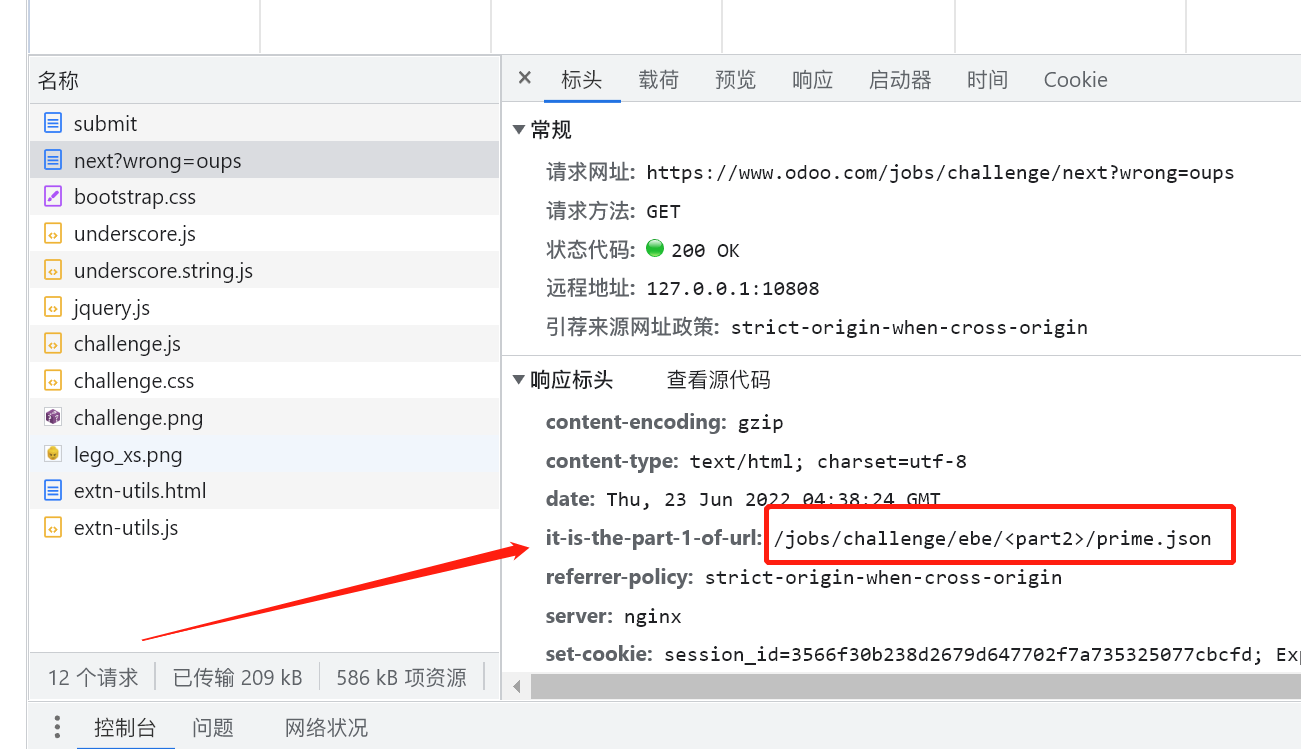
请求头也有一个奇怪的信息
| name | value |
|---|---|
| It-Is-The-Part-1-Of-Url | “/jobs/challenge/ebe/ |
这时候我们可以分析, 这个 URL 被分为了两部分, 放到一起看一下
1 | /jobs/challenge/<part1>/1d1/prime.json |
那么完整的 URL 应该是
1 | /jobs/challenge/ebe/1d1/prime.json |
我们尝试访问这个 URL
得到一串 JSON
1 | { |
翻译一下, 大概意思是, 把这个数组里的非素数删除了, 然后将剩余的数字右移x位(也许是位运算?), 然后就得到了密码

x 位指的是应该是 pi 的第 222 位的数字
至此, 我们梳理一下完整的逻辑, 把上面给定的数组里的非素数删除, 然后找到 pi 的第 222 位的值 x, 然后将数组中剩余的数字按位运算右移 x 位.
网上找一个高效的判断是否位素数的函数
1 | def is_prime(x: int) -> bool: |
查一下 pi 的第 222 位是几, 这里可以自己写函数计算也可以直接在网上查, 这里仅仅需要知道该值即可, 所以我选择了直接在网上查
直接在网站
1 | http://pai.babihu.com/ |
查的 pi 的 222 位为 8

还记的最开始的提示吗?
1 | Hint: ascii |
这里运算完的应该是 ascii 码, 我们计算出对应的字符就得到了最后的密文, 至此我们开始编写解码函数
1 |
|
解密得密码
1 | c5b2b5e58aaff41868a8d7bf4cea6efc2eb6ce68 |
本关通过

本关注意到这个图片变得奇怪了, 事出反常必有妖!
我们仔细翻翻跟服务器的请求里有没有什么奇怪的东西.

这个就是请求的图片

看起来非常像密码对不对? 突破口一定在这副怪异的图片里.
该请求响应了一个 HTML, 里面全都是 span 标签, 我们尝试把 span 标签的 style 属性去除了(因为我分析应该和密文关系不大),
然后删除 # 这个字符, 看看最后还能剩下什么.
我意外的发现在 Chrome 开发工具的预览窗口可以直接过滤掉 style 属性, 这下就好办了.
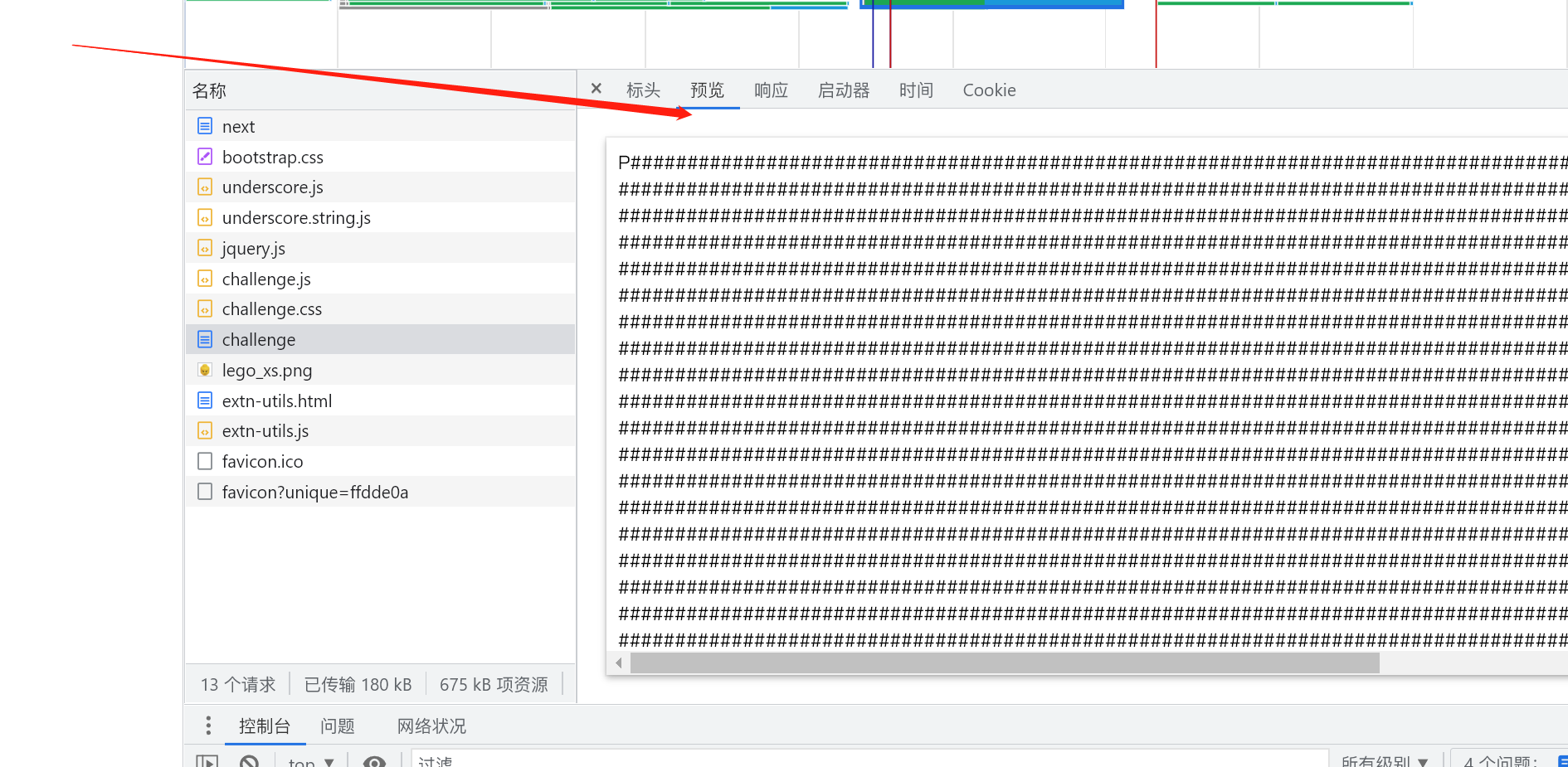
我们把这些内容复制出来, 然后删除 #
已经可以看出来密码了

稍微整理下得到
1 | Password:'7f593a77ef76c1f04d1cc5bc51aebf265559b965' |
通关

注意红框框住的地方
1 | b'iVBORw0KGgoAAAANSUhEUgAAAMgAAADICAIAAAAiOjnJAAAABmJLR0QA/wD/AP+gvaeTAAAE/klEQVR4nO3dwW7bOBSG0clg3v+VM7suhJSQTH4UW5yzbFxJcX4QNH15+fX9/f0PrPbv2w/A30mwSAgWCcEiIVgkBIvEfz/+69fX157bXxY7Lvd99NOxR7/R+MoLH/KQ33fG757KiEVCsEgIFgnBIvHz5P1i4feJM5PKmYnwzKeEzsKnGr85+/+CRiwSgkVCsEgIFolbk/eLhavY24yfeWa5fOGVH71XM2/shr+gEYuEYJEQLBKCReKTyXtnZgW8W1ufKW6ZudHMU73OiEVCsEgIFgnBInHW5P2iq4jvprp/xENuYMQiIVgkBIuEYJH4ZPL+1sx3/OKF91344plLdcUtGz4WGLFICBYJwSIhWCRuTd63beB85FGBysyS98Kyme6nY/v/gkYsEoJFQrBICBaJnyfvhxRsnPmhYaE/sS7oJiMWCcEiIVgkBIvE7m4zC1fAFy61P9Itpm9bW19Yj6TPO1sJFgnBIiFYJHZvWF04ie7KZg6xsPfOwvvevLIRi4RgkRAsEoJFYvfkfeakoRlvHU+6cEvq2CGV+L8YsUgIFgnBIiFYJL5+nHzNTLEX/t+ZJeBtnxIe3WjbGzvzXi15c4xYJASLhGCRECwSC2reZxa1u0nltqKatwpUZn7Bmcew8s6bBIuEYJEQLBKfdJvp9kbOVHmPrzzzf7ct8XfNZx5R8865BIuEYJEQLBI/l82E98u6P26b215s69V+cXhBjhGLhGCRECwSgkXi55X3biNlV8Y+vm83xe6WyxeW+nQFOb9jxCIhWCQEi4Rgkbi18t4tEG9bLn9rjfuQif/+v4IRi4RgkRAsEoJF4pNuM2OHrK2PXzy28DNEt7m3az6zhBGLhGCRECwSgkXik5X3t2aR25pQjv0R3xZcbPvy4BcjFgnBIiFYJASLxIKymf0Twzv/d2zbttLxfcfe+v5jzIZV3iRYJASLhGCRuFU281Zjk0dP9Uh3qYW2FSA9eoybjFgkBIuEYJEQLBILWkVuK+vedojoIeXz3UeoR/R55yCCRUKwSAgWiVutIruF6YW15zMe3XfbFwBvbRdwwirnEiwSgkVCsEj8PHm/eGuNe+bFM0ebztx3Yb3Ktt70C3/6ixGLhGCRECwSgkViQavI/ad33rnRX998pttVe2HlnYMIFgnBIiFYJD7ZsDp+8dghW0O7qX13suu2BjIXNqxyEMEiIVgkBIvErbKZR7q9oNt2ii58jJkbXXTfFox/qs87BxEsEoJFQrBILFh573SbXceXGtu2YfWtZjtLGLFICBYJwSIhWCTW93l/5Myl5/29We7c9y1q3jmIYJEQLBKCRWJBn/eFth3/9Nbmz7G3Osg/otsMbxIsEoJFQrBI3Orz3hl3Np+51MXC6Wp3OtIhh0MtqcAxYpEQLBKCRUKwSNzasHrIcUgXCyekC1+8cNZ8udRbJ1h9xohFQrBICBYJwSLxSbeZbhZ5SIX4wi8Auq6TF9u+WrjJiEVCsEgIFgnBIrG+VeRCj+by29qgd11uxkvtXdl+0YvGiEVCsEgIFgnBInH05H1m6fmQxooL6+W3ndk0puadNwkWCcEiIVgkPpm8dxPDmdORZirEH1lY29Md9LqwXOczRiwSgkVCsEgIFolbk/e3Wid2x7GO57bbTli96NbW928mMGKRECwSgkVCsEic1eedv4YRi4RgkRAsEoJFQrBICBYJwSLxP3LS5YIohRy8AAAAAElFTkSuQmCC' |
这里是一串不知名的代码, 不过看开头非常像 PNG 格式的图片 Base64 编码后的格式
随便输一个密码看看有没有什么提示.
提示
1 | Hint: png |
我现在很确信这是一个 png 格式的图片 base64 编码后的代码
直接在网上还原该图片得到了一个二维码

继续识别一下该二维码则直接得到结果
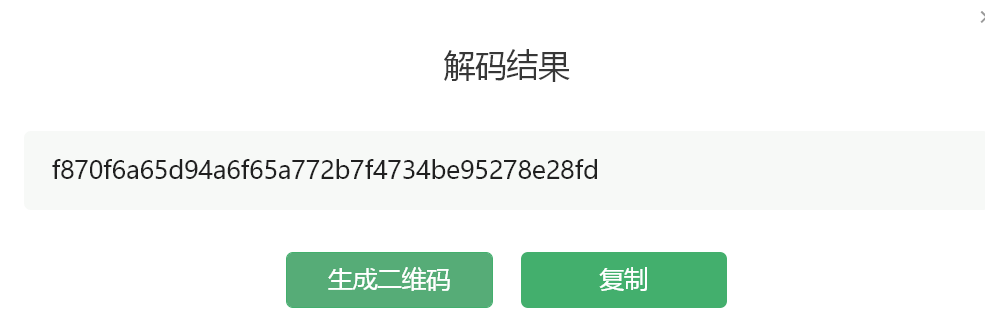
1 | f870f6a65d94a6f65a772b7f4734be95278e28fd |
通关

本关给了一个加密函数的两个版本, js 和 python, 我比较熟悉 python 我们就来看下这个 python 函数的逻辑
1 | def r(pwd, fr, to, by): |
逻辑很简单, 该函数每次取出密码指定位的字符.
再看看输出结果
1 | print(r(pwd, 0, 4, 1)) |
观察函数 r 的第三个参数, 我们发现最大值位 40, 该参数对应 range() 函数的第二位即 max.
于是我们可以知道 pwd 的长度位 40, 解码函数的逻辑就很清楚了.
创建一个长度 40 的数组, 然后将上述输出的结果依次填到数组的指定位置即可
开始编写解码函数
1 | # 创建一个 40 长度的数组 |
然后依次执行
1 | decrypt("edac", 0, 4, 1) |
拼接结果
1 | print("".join(_pwd)) |
得到密码
1 | edace17e62741b6ac51562a12ddff38cbfe53dcd |

最后一关就有点难度了
因为你如果密码不正确的话是无法提交的, 也就是说没有任何的提示. 跟服务器也没有什么交互.
我们只能先取看看网页源码里有什么线索没有
果然发现了端倪, 源码里有一段 js 脚本, 看逻辑应该是处理提交密码的, 仔细分析下.
1 | <script type="text/javascript"> |
有几个变量我们需要注意下
1 | ts |
我们直接在浏览器的控制台执行下面的代码看看有什么结果没有
1 | ts = $("#pwd").data('ts')+''; |

然后我们往下看是一个条件判断
1 | (parseInt(pwd.slice(-(--([,,,undefined].join()).length))[0]) * parseInt(pwd.slice(0 - - - 1 - - - - - 1 - - - - 0)[1]) * stmnt.split("All").length == ts.slice(eval(""+''+""+ƒ(1<0)+""+"-"+''+""+ƒ(0<1)+"-"+ƒ(1>0)))) |
太长了我们可以拆分一下
1 | parseInt(pwd.slice(-(--([,,,undefined].join()).length))[0]) |
简单来讲就是上面三行的乘积需要等于下面该行的值
1 | ts.slice(eval(""+''+""+ƒ(1<0)+""+"-"+''+""+ƒ(0<1)+"-"+ƒ(1>0))) |
因为我们现在需要反推pwd这个值, 所以上面不涉及pwd变量的我们可以直接在控制台执行看看具体的值是多少
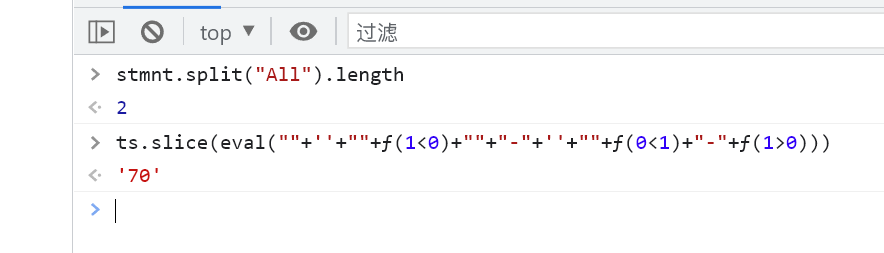
| code | value |
|---|---|
| stmnt.split(“All”).length | 2 |
| ts.slice(eval(“”+’’+””+ƒ(1<0)+””+”-“+’’+””+ƒ(0<1)+”-“+ƒ(1>0))) | ‘70’ |
这里注意到变量类型不同, 但是我们也看到了这个条件匹配用的是 ==, 即不是严格模式! 所以我们可以把他们都当成数字来处理
接下来我们处理包含 pwd 变量的条件
我们把
1 | parseInt(pwd.slice(-(--([,,,undefined].join()).length))[0]) |
记作 a
1 | parseInt(pwd.slice(0 - - - 1 - - - - - 1 - - - - 0)[1]) |
记作 b
则上述条件可以变为
1 | a * b * 2 == 70 |
则可知 a b 的可选值表
| a | b |
|---|---|
| 1 | 35 |
| 35 | 1 |
| 5 | 7 |
| 7 | 5 |
我们把
1 | -(--([,,,undefined].join()).length) |
在控制台里执行下, 然后得到值 -2
于是
1 | parseInt(pwd.slice(-(--([,,,undefined].join()).length))[0]) |
于是我们可以分析出 a 表达式为 pwd 变量的倒数第二字符所代表的值
同理我们分析 b 表达式
1 | parseInt(pwd.slice(0 - - - 1 - - - - - 1 - - - - 0)[1]) |
b 表达式为 pwd 变量的倒数第一字符所代表的值
仔细观察 js 脚本还记不记得这句
1 | pwd = $("#pwd").val(); |
意思是 pwd 取到的是一个字符串变量, 观察我们刚才的 a, b 取值表.
我们发现按下标从一个字符串里取值, 取到的一定是一个字符, 不可能为两个字符, 于是现在 a / b 取值表就变为
| a | b |
|---|---|
| 5 | 7 |
| 7 | 5 |
也就是说 pwd 的最后两位一定是 57 或 75
我们再往下看
1 | 0===pwd.lastIndexOf(multi.toString().substr(1,4)+stmnt.substring(2,6),0) |
我们先看一下里面的具体值是什么.
1 | multi.toString().substr(1,4)+stmnt.substring(2,6) |
查看一下 lastIndexOf 方法的说明
参考链接
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/lastIndexOf
lastIndexOf() 方法返回调用String 对象的指定值最后一次出现的索引,在一个字符串中的指定位置 fromIndex处从后向前搜索。如果没找到这个特定值则返回-1 。
该方法将从尾到头地检索字符串 str,看它是否含有子串 searchValue。开始检索的位置在字符串的 fromIndex 处或字符串的结尾(没有指定 fromIndex 时)。如果找到一个 searchValue,则返回 searchValue 的第一个字符在 str 中的位置。str中的字符位置是从 0 开始的。
简单来讲, 就是想要
1 | 0 === pwd.lastIndexOf(multi.toString().substr(1,4)+stmnt.substring(2,6),0) |
这个表达式成立, pwd 这个变量一定是 multi.toString().substr(1,4)+stmnt.substring(2,6) 所表示的值 4380Odoo 作为开头
又因为 pwd 的最后两位一定是 57 或 75, 所以可以猜测密码应该为
1 | 4380Odo |
这两个其中的一个
大功告成!

1 | class Singleton(type): |
1 | class Singleton(object): |
1 | def singleton(cls): |
1 | class Singleton(object): |
Python的模块是天然的单例模式
在一个py文件中, 多次导入同一个模块, 这个模块也只有在第一次的时候被导入, 后续的该模块导入语句都不会再执行了
参考链接
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足
例如:
1 | 输入:s = "()" |
1 | 输入:s = "()[]{}" |
1 | 输入:s = "(]" |
即左右括号必须是闭合的。
使用栈结构来处理这个问题非常简单。
我们从左到右依次扫描字符串的每一个字符,如果是([{左括号就入栈,如果是)]}右括号就从栈里弹出栈顶的元素,然后匹配该字符和栈顶元素是否是成对的。
例如扫描到字符(,然后栈顶元素是),则成对,否则不成对则返回False
扫描完字符串,如果栈里没有元素则说明括号都是成对的,匹配成功。
1 | class Solution: |
原链接
记录一次奇怪的 DEBUG 过程
事情的起因是我在搭建一个前端项目, 第一次打开可以, 但是如果再刷新页面则会报错.
仔细查看我的代码, 发现没有什么问题, 最后跟踪错误到了vue-router
控制台报错
1 | Uncaught (in promise) TypeError: api.now is not a function |
继续跟踪
1 | api.addTimelineEvent({ |
如果出错的地方在业务逻辑, 则可以很容易的找出错误原因, 但是这个地方报错, 让我毫无头绪.
Google …
没想到还真的找到了解决方案, 而且还就在该文章发布时间的前半个月(还热乎着…)
That’s from the Vue devtools plugin. And only happens if you are still on the 6.0 beta of Vue devtools.
Happened to me today when checking in another browser that still was on the 6.0 beta version instead of the stable one we released recently.
Solution: remove the beta, upgrade to the stable release
大意是说, 如果你开发时使用了 Vue Devtools 这个插件, 并且还是 6.0 beta 版本时, 就会发生这个问题.
解决方案也很简单, 卸载这个测试版, 安装稳定版
https://chrome.google.com/webstore/detail/vuejs-devtools/nhdogjmejiglipccpnnnanhbledajbpd
现在想想, 这个插件我一年前装的, 然后就没管过, 我不清楚它会不会自动更新, 但是确实在我意想不到的地方给我挖了个大坑….
这个事情总结出什么经验呢?
BUG 有时候就是发生的这么毫无逻辑…让人捉摸不定
参考链接
在 Python 中经常会做的一件事就是将某个对象序列化, 序列化有很多种方式, JSON 是最常用的其中一种(方便和前端交换数据).
但是一个明显的问题是, Python 标准库json, 仅仅能dumps其内置的基本数据类型, 例如 string, integer, boolean, list, dict …
并且 JSON 作为一种数据交换格式, 有其固定的数据类型.
有时候我们需要将我们编写的一个类序列化, 此时该怎么办?
如果 json.dumps 一个非标准类型(例如一个我们编写的类)会发生什么事?
我们先定义一个类Person
1 | class Person: |
尝试用 json 序列化
1 | import json |
毫不意外的报错了
1 | --------------------------------------------------------------------------- |
我们仔细观察报错信息, 提示 Person 不是一个 JSON 序列化对象
1 | TypeError: Object of type Person is not JSON serializable |
那么问题来了, 我们如何把各种各样的 Python 对象序列化成 JSON 格式?
Google 和查阅官方文档后你会发现 dumps 方法提供了一个 cls 参数, 我们可以自己编写一个序列化类, 告诉该他该如何dumps这个对象.
例如
1 | class PersonEncoder(json.JSONEncoder): |
我们再尝试一下
1 | json.dumps(p, cls=PersonEncoder) |
得到结果
1 | '{"name": "naonao"}' |
成功了, 完美的解决了问题.
但是现在有一个问题, 如果序列化少量类, 我们只需要在default这个方法下编写少量的代码即可. 但通常一个应用不可能仅仅只有几个少量的类, 类多了怎么办?
1 | def default(self, _object): |
这种写法, 一点也不优雅!
我们需要一种更优雅的解决方案
该函数可以解决这个问题
1 | from functools import singledispatch |
我们先创建两个类
1 | import json |
创建两个实例
1 | person = Person() |
接下来我们可以这样定义序列化器
1 |
|
尝试一下
1 | data = { |
完美解决
1 | '{"person": {"name": "naonao", "age": 18}, "animal": {"name": "dog"}}' |
接下来有新的类(或是数据类型)进行序列化时, 我们仅仅需要参照这个格式
1 | # 目标类 |
编写对应的解析器即可. 这样可比 if else ...循环嵌套可读性高了不知多少倍!
参考链接
1 | class Person: |